
With the right agentic harness, an LLM can scale from surface-level answers to deep insight—the kind high-science teams can depend on.
As many as half of all professionals use LLMs at work every day. Why? They’re informative: they give us rapid information when we don’t have much time or a quick answer when we don’t want to invest in conducting research. But often, the LLM interaction—while informative—is not that useful for deep insight. The output has a black-box quality that can be hard to explain, is subject to hallucination that can be hard to detect, and can take time to parse into useful formats for deeper analysis.
The truth is LLMs need something more to be an engine for extracting business-critical information in a highly scientific industry: they need an agentic harness.
Moving from “Quick Answers” to “Strategic Insights”
What do we mean by an “agentic harness”? An agentic harness is a structured AI workflow that orchestrates retrieval, reasoning, validation, and data persistence so an LLM can reliably perform complex, multi-step analytical tasks with controlled autonomy. While that may sound complicated, this kind of workflow can be surprisingly straightforward to get up and running. In fact, when our Data and Insights vertical saw a recent report arguing that GLP-1s might be the first longevity drugs, we decided to satisfy our own curiosity and demonstrate what we mean with a simple example.
Mapping the GLP-1 Trial Universe
The same article suggesting that GLP-1s are the first longevity drugs also highlighted their potential utility in a range of other conditions, some we had heard about and some we hadn’t. To understand the areas where GLP-1s are being tested clinically, we decided to build a map of the GLP-1 clinical trial universe to better understand the emerging trends and objectively assess the reality on the ground.
Data Retrieval: We extracted all trials registered in ClinicalTrials.gov for 19 active ingredients that activate the GLP-1 receptor (including more recently developed dual and triple agonists). For this exploratory analysis, we relied heavily on various fields of each clinical trial record, assuming that those fields generally contained accurate information. After basic data cleaning and filtering, we had a dataset of more than 1000 trials, reflecting the size and complexity of the drug class.
Data Annotation and Classification: Often, this would be when many lean biotech teams might get stuck: making sense of these data requires substantial classification and annotation to address inconsistent terminology or missing data. Instead, we used an LLM in a simple agentic harness to do this work for us, along with a checkpoint for human review. While we won’t get into all the technical details, we accomplished this by using prompting strategies that guide the LLM to respond in very specific ways, by including access to additional databases for consistent annotation, and by enforcing simple internal quality checks to automatically detect and remove hallucinations at key steps. The code for this project is available as an open-source repository on GitHub.
What We Found: TLDR version: we’re pretty glad we weren’t doing this by hand.
Even mapping a small subset of the information in our dataset yielded a complex graph representing thousands of structured relationships between drugs, trials, sponsors, conditions, and therapeutic categories. Fortunately, this is exactly the type of information that LLM agents with the right tools can traverse, analyze, and extract additional insights from, providing a long-term resource that we can query and update with more information going forward.

Returning to our original question—identifying trends in how GLP-1 clinical trials may be shifting from primarily metabolic or endocrine conditions—the workflow provided the clarity to satisfy our curiosity.
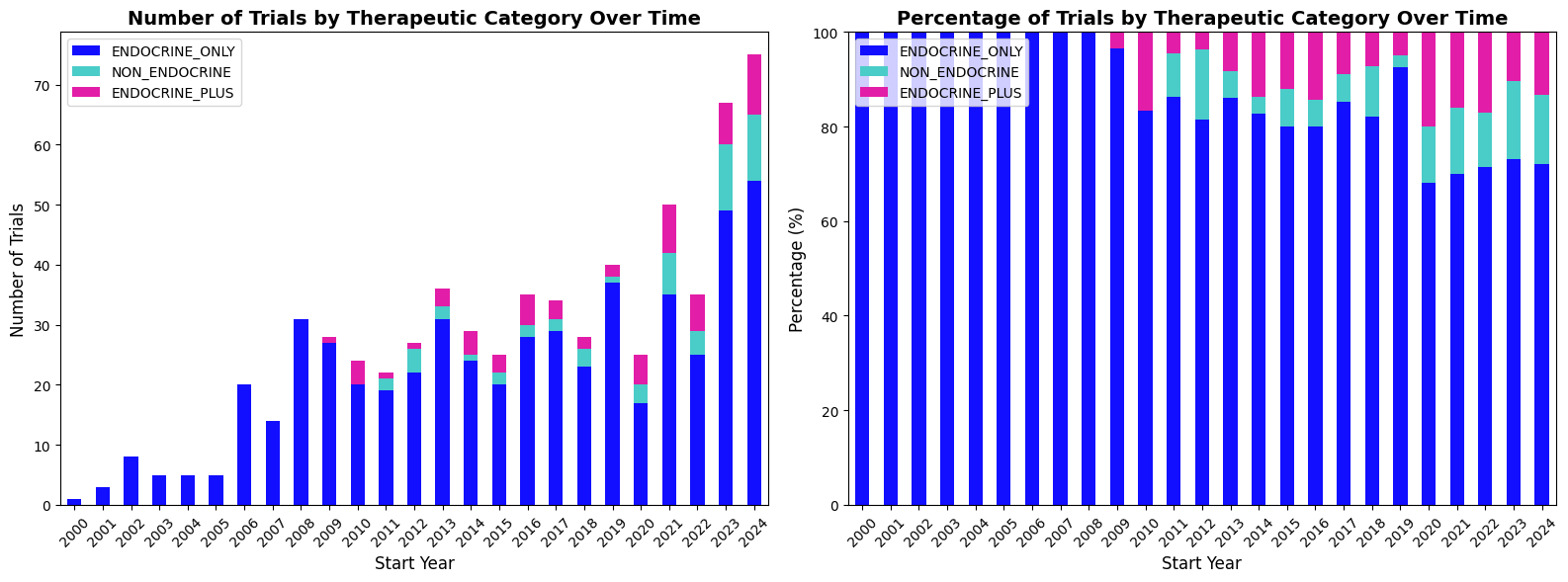
When we focus on Phase 2 and Phase 3 trials—those most likely to evaluate efficacy—we see that by 2024, over 20% of trials in our dataset targeted Non-Endocrine conditions. While some evaluated both Endocrine and Non-Endocrine indications (e.g., diabetes and heart failure), trials centered solely on Non-Endocrine conditions were more common, with CNS disorders—including Parkinson disease, Alzheimer disease, and major depressive disorder—representing the largest share.

These shifts suggest that GLP-1s are increasingly being positioned as multi-system therapeutics, which has implications for competitive differentiation, trial recruitment, and indication-sequencing strategy. Because we’ve persisted the data in our knowledge graph, the analysis and workflow could be extended to dive deeper into the strategic questions around any of these topics going forward.
From Concept to Competitive Advantage
Setting up our project did require domain knowledge and some coding ability, but the process was straightforward and scalable.
The type of analyses we performed could be extended easily:
- To understand the recruitment rates for trials with different endpoints and designs – critical for budgeting and long-range planning
- To determine the flux of participants required to fully enroll open trials in a competitive space – necessary to set a realistic recruitment timeline, or to identify promising alternative indications that could be pursued with less competition
- To cross-reference other databases to understand trends in successful vs unsuccessful trials or to find where “dark data” may be living in a condition of interest – essential for determining an optimal study design or to avoid going down a path that has been tested unsuccessfully
The capability of the agentic harness could be broadened using straightforward approaches:
- To make the workflow more agentic by allowing it flexibility to design searches or suggest annotations and analyses to execute on – very doable with multiple orchestration frameworks
- To connect the knowledge graph as part of a Graph RAG framework – multiple approaches exist to allow real time discussion and analysis of the connections between data points
- To embed the workflow as an extension of a platform you may already use – very feasible with Claude desktop, Microsoft Copilot, etc
Right now, we think the principle is just as important as any of these implementations: AI and LLMs can be reliable and trustworthy accelerators for data and insight mining – but only when placed inside the right agentic harness—because in biotech, it’s not the model alone that creates insight, but the workflow around it.
Kynetyk is a new type of partner for the biotech and life sciences industry: an Applied AI company focused on designing strategies that are accessible, practical, and effective for companies of any size. Reach out to us at hello@kynetyk.ai. We’d love to connect.